

This post is a joint collaboration between Salesforce and AWS and is being cross-published on both the Salesforce Engineering Blog and the AWS Machine Learning Blog.
The Salesforce AI Platform Model Serving team is dedicated to developing and managing services that power large language models (LLMs) and other AI workloads within Salesforce. Their main focus is on model onboarding, providing customers with a robust infrastructure to host a variety of ML models. Their mission is to streamline model deployment, enhance inference performance and optimize cost efficiency, ensuring seamless integration into Agentforce and other applications requiring inference. They’re committed to enhancing the model inferencing performance and overall efficiency by integrating state-of-the-art solutions and collaborating with leading technology providers, including open source communities and cloud services such as Amazon Web Services (AWS) and building it into a unified AI platform. This helps ensure Salesforce customers receive the most advanced AI technology available while optimizing the cost-performance of the serving infrastructure.
In this post, we share how the Salesforce AI Platform team optimized GPU utilization, improved resource efficiency and achieved cost savings using Amazon SageMaker AI, specifically inference components.
The challenge with hosting models for inference: Optimizing compute and cost-to-serve while maintaining performance
Deploying models efficiently, reliably, and cost-effectively is a critical challenge for organizations of all sizes. The Salesforce AI Platform team is responsible for deploying their proprietary LLMs such as CodeGen and XGen on SageMaker AI and optimizing them for inference. Salesforce has multiple models distributed across single model endpoints (SMEs), supporting a diverse range of model sizes from a few gigabytes (GB) to 30 GB, each with unique performance requirements and infrastructure demands.
The team faced two distinct optimization challenges. Their larger models (20–30 GB) with lower traffic patterns were running on high-performance GPUs, resulting in underutilized multi-GPU instances and inefficient resource allocation. Meanwhile, their medium-sized models (approximately 15 GB) handling high-traffic workloads demanded low-latency, high-throughput processing capabilities. These models often incurred higher costs due to over-provisioning on similar multi-GPU setups. Here’s a sample illustration of Salesforce’s large and medium SageMaker endpoints and where resources are under-utilized:
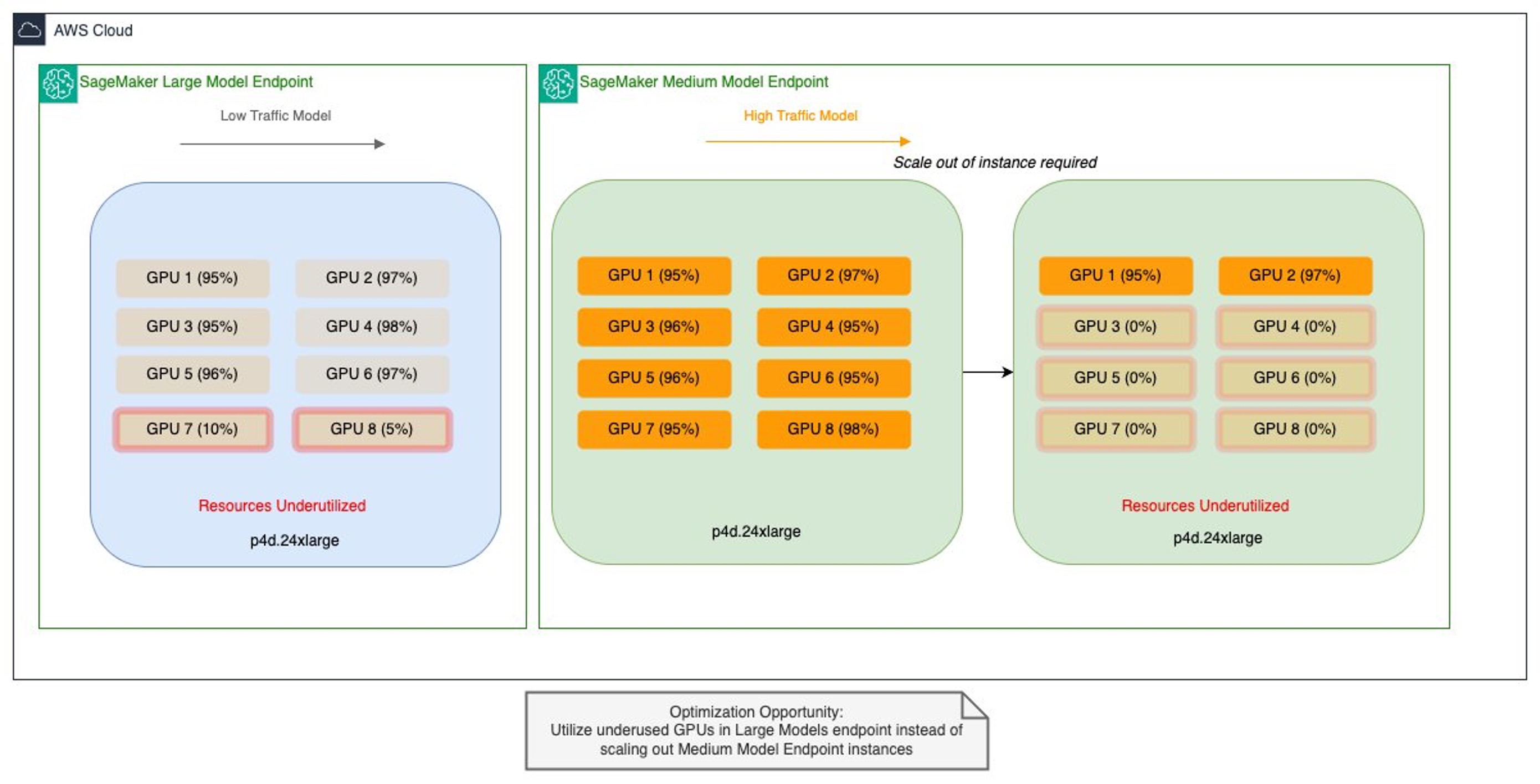
Operating on Amazon EC2 P4d instances today, with plans to use the latest generation P5en instances equipped with NVIDIA H200 Tensor Core GPUs, the team sought an efficient resource optimization strategy that would maximize GPU utilization across their SageMaker AI endpoints while enabling scalable AI operations and extracting maximum value from their high-performance instances—all without compromising performance or over-provisioning hardware.
This challenge reflects a critical balance that enterprises must strike when scaling their AI operations: maximizing the performance of sophisticated AI workloads while optimizing infrastructure costs and resource efficiency. Salesforce needed a solution that would not only resolve their immediate deployment challenges but also create a flexible foundation capable of supporting their evolving AI initiatives.
To address these challenges, the Salesforce AI Platform team used SageMaker AI inference components that enabled deployment of multiple foundation models (FMs) on a single SageMaker AI endpoint with granular control over the number of accelerators and memory allocation per model. This helps improve resource utilization, reduces model deployment costs, and lets you scale endpoints together with your use cases.
Solution: Optimizing model deployment with Amazon SageMaker AI inference components
With Amazon SageMaker AI inference components, you can deploy one or more FMs on the same SageMaker AI endpoint and control how many accelerators and how much memory is reserved for each FM. This helps to improve resource utilization, reduces model deployment costs, and lets you scale endpoints together with your use cases. For each FM, you can define separate scaling policies to adapt to model usage patterns while further optimizing infrastructure costs. Here’s the illustration of Salesforce’s large and medium SageMaker endpoints after utilization has been improved with Inference Components:
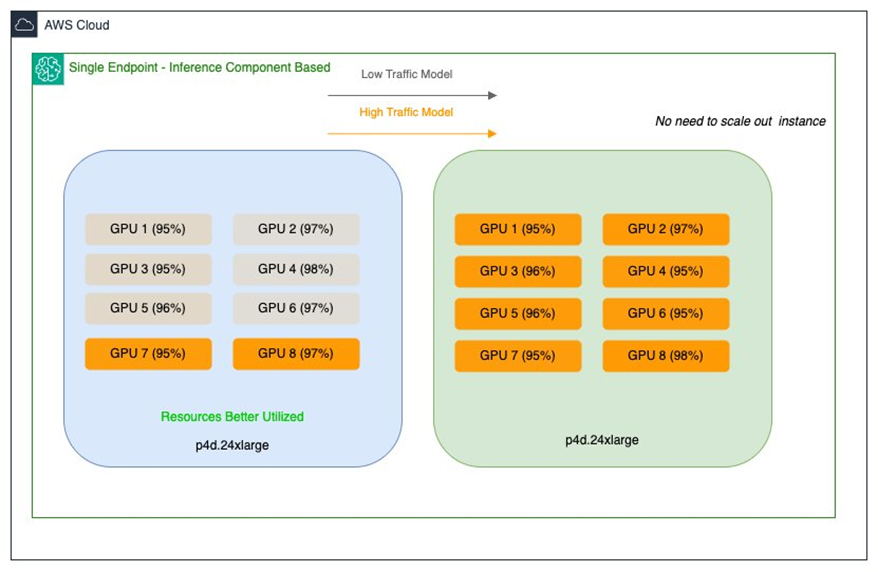
An inference component abstracts ML models and enables assigning CPUs, GPU, and scaling policies per model. Inference components offer the following benefits:
- SageMaker AI will optimally place and pack models onto ML instances to maximize utilization, leading to cost savings.
- Each model scales independently based…
Source link


