

When your application can call many different LLMs with very different prices and capabilities, who should decide which one answers each request? Salesforce AI research team introduces ‘xRouter’, a tool-calling–based routing system that targets this gap with a reinforcement learning based router and learns when to answer locally and when to call external models, while tracking cost at token level.
What is xRouter?
xRouter is a tool calling based orchestration system built on Qwen2.5-7B-Instruct as the router backbone. The router is an instruction tuned model with tool calling capabilities that decides which downstream model to invoke, how to prompt it, and whether to synthesize or select an answer. The implementation uses DAPO, Distributional Advantage Policy Optimization, inside the Verl reinforcement learning framework, and exposes an OpenAI compatible API.
The router operates over more than 20 LLM tools in the full system. These tools span premium, standard, budget and specialized tiers, including GPT-5, GPT-4.1, GPT-5-Mini, GPT-5-Nano, o3, Kimi K2, DeepSeek-R1, Qwen3-235B variants and GPT-OSS models. The offloading pool is a 12 model subset that includes GPT-5, GPT-5-Mini, GPT-5-Nano, GPT-4o, GPT-4.1, o3, o3-Pro, o4-Mini, GPT-OSS-120B, GPT-OSS-20B and two Gemini-2.5 variants.
Cost Aware Reward and Success Gating
Routing is framed as a reinforcement learning problem. For each episode, the reward combines a binary success signal and a cost penalty. The research team defines a reward that gives a fixed bonus when the final answer is correct, then subtracts a term proportional to the total normalized cost of all model calls. If the answer is wrong, the reward is zero regardless of how cheap it was.
As per the Model weights page, reward = quality − λ × normalized_cost, where λ is a cost penalty coefficient. Episodes with failures effectively have zero quality. This ‘success gated, cost shaped’ objective forces the router to first achieve correctness, then optimize cost among successful strategies. In practice, training uses 3 cost penalty settings, which produce the xRouter-7B-1, xRouter-7B-2 and xRouter-7B-3 variants.
Training Data and Signal Design
xRouter training data comes from Reasoning360, which includes math, code and general reasoning tasks with difficulty estimates derived from a strong reference model, Qwen3-32B. The research team stratify samples into easy, medium and hard bands, and add simpler chit chat, retrieval and factual questions to teach the router when it can answer directly without delegation. Each sample includes descriptions and prices for models from different tiers. The system also refreshes the model catalog and perturbs costs to avoid overfitting to a static price table.
Failed trajectories, such as wrong answers from expensive models or unnecessary calls when the router could have answered itself, still incur full cost and receive zero reward. This produces a clean learning signal, where correctness gates reward and cost shapes the routing policy.
How the Router Behaves at Inference Time?
The router supports three execution modes. It can answer directly from the backbone without calling tools. It can call one or more downstream models, then synthesize a response using its own reasoning over their outputs. It can also call downstream models and use a special select_response tool to pick one of the replies as the final answer. These modes are implemented through function calls in an OpenAI style interface, which the orchestration engine executes through LiteLLM and SGLang.
Empirically, trained xRouter instances use a mix of direct and synthesized responses. Off the shelf routers such as GPT-4o, GPT-4.1, GPT-5, Qwen2.5-7B and Qwen3-8B tend to respond directly most of the time, even when instructed to offload when uncertain. This is an important behavioral difference and explains part of the efficiency gain.
Quantitative Results and Cost Utility
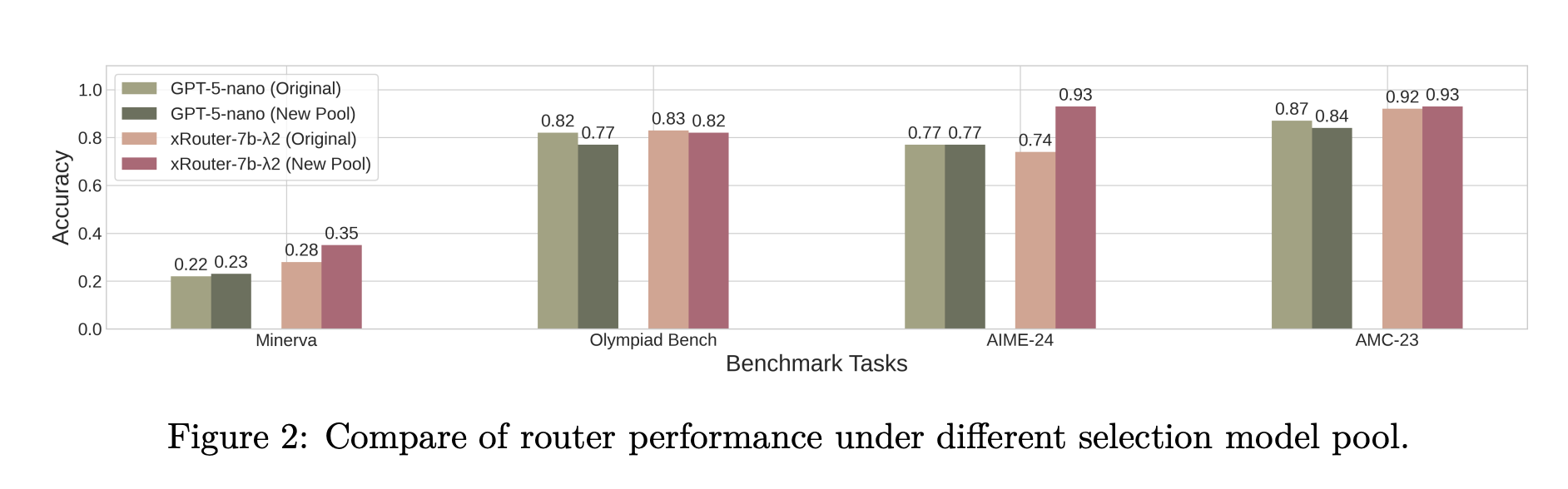
On static routing baselines across Minerva, MATH-500, Olympiad Bench, AIME-24, AMC-23, Codeforces, Code-Contests and Human-EvalPlus, xRouter-7B variants consistently improve accuracy compared to using the same base model as an untrained router. xRouter-7B-2, for example, reaches near GPT-5 accuracy on Olympiad Bench while using about one eighth of the GPT-5 evaluation cost.
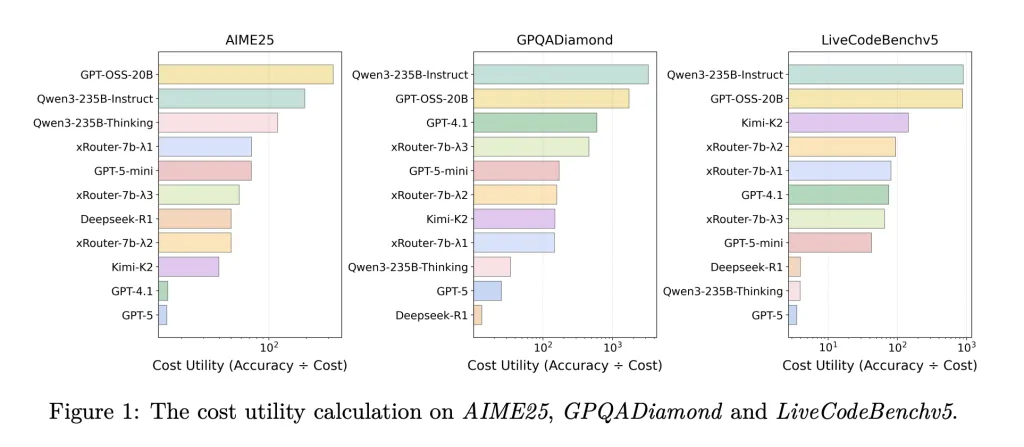
In the system level comparison on LiveCodeBenchv5, GPQADiamond, AIME25, MT-Bench, IFEval and LiveBench, xRouter-7B-3 achieves the highest average accuracy on LiveCodeBenchv5 among all tested systems, and does this with moderate cost. Across tasks such as GPQA, xRouter variants reach around 80 to 90 percent of GPT-5 accuracy while consuming less than one fifth of the cost. The research team summarize that their cost aware reward can reduce inference cost by up to 80 percent at similar completion rates. The model…
Source link


